OpenAI Sora如何使用? 手把手教你Sora申请方法。本文有Sora如何申请、Sora呈现能力、Sora提示工程、Sora原理剖析、Sora应用展望五方面。
如需代注册帐号或代充值Chatgpt Plus会员,请添加客服微信:GPTplus8688
| ChatGPT | | 【推荐】wildcard一键升级chatgpt4.0保姆级教程| 国内无需手机验证码GPT注册| [订阅ChatGPT等海外软件常见问题详及其解决方案解 | |
|---|---|
| WildCard虚拟卡 | | 【推荐】wildcard虚拟信用卡平台详解,订阅ChatGPT等海外软件常见问题详及其解决方案解 | |
| Onlyfans | |【推荐】OnlyFans支付教程 | |
| Sora | |OpenAI Sora:60s超长长度、超强语义理解、世界模型。浅析文生视频模型Sora以及技术原理简介 | [OpenAI Sora如何使用? 手把手教你Sora申请方法。本文有Sora如何申请、Sora呈现能力、Sora提示工程、Sora原理剖析、Sora应用展望五方面。 | |
| Midjourney | |【推荐】国内如何购买midjourney? | |
已有GPT官方账号不会升级GPT4请参考:【保姆级】国内如何用gpt4?如何升级gpt4?用wildcard一键升级chatgpt4.0保姆级教程
[TOC]
最新的GPT注册升级链接100%直达:WildCard最新 | 一分钟开卡,轻松订阅海外软件服务
引言:OpenA推出首款AI视频模型Sora,震惊世界!
Sora是什么?
Sora是OpenAI最新发布的文本生成视频(Text to Video)大模型,能生成长达60秒的视频
Sora能够创造出包括多个角色、特定动作类型以及对主题和背景的精确细节描述的复杂场景,对语言的理解非常深刻,使其能够精准地识别用户的指令,并创造出表情丰富、情感生动的角色。此外,Sora还能在同一视频内制作多个镜头,同时确保角色的形象和整体的视觉风格保持一致。
Sora是基于DALL·E 3和ChatGPT模型的研究成果。它采用了DALL·E 3中的recaptioning technique,为视觉训练数据生成详细描述的标题。因此,模型能更准确地遵循用户在生成视频中的文字指令。
除了能从文字指令生成视频外,Sora还能将现有静止图像转化为视频,准确地动态展现图像内容并关注细节。此外,它还能扩展现有视频或填补视频中缺失的画面。
一、Sora如何申请
截至2024-02-25,Sora还没有面向大众开放测试,只有少数人有Sora的测试权限。当然有试用申请通道,但申请通过率不会高
如何申请?(据官方透露的消息,OpenAI近期大概率会宣布将Sora首批开放给Chatgpt Plus用户申请使用。所以,请务必提前准备好Chatgpt Plus。)
1、登录官网选择red-teaming-network申请:https://openai.com/form/red-teaming-network
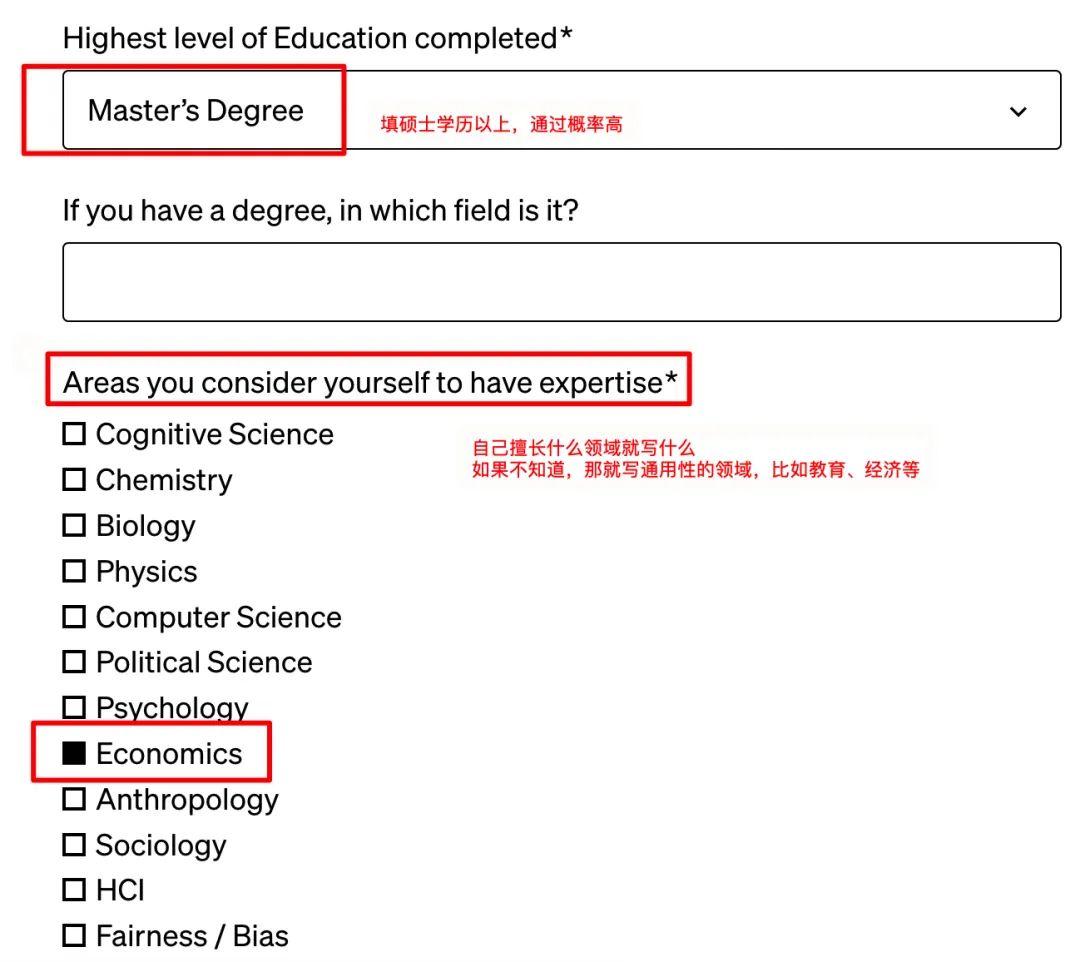
2、填写表单:建议填写资料用英文。*为必填项,包括你的学历、公司、专业强项、计划如何使用Sora等等。如果自己不会写,可以参考案例,注意输入框有字数限制,别超过,否则会显示不全,影响申请。
3、提交Submit
参考填写表单如下图:

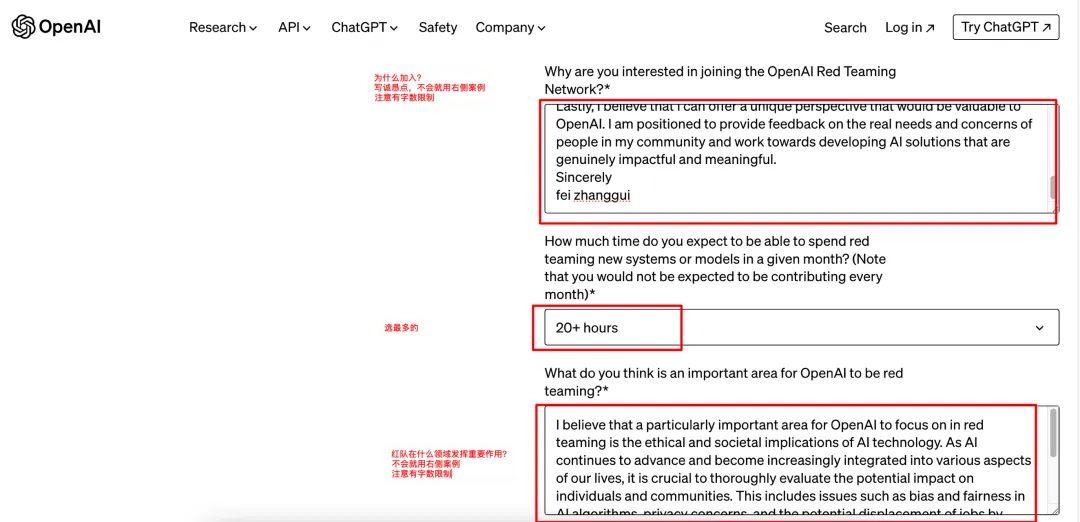
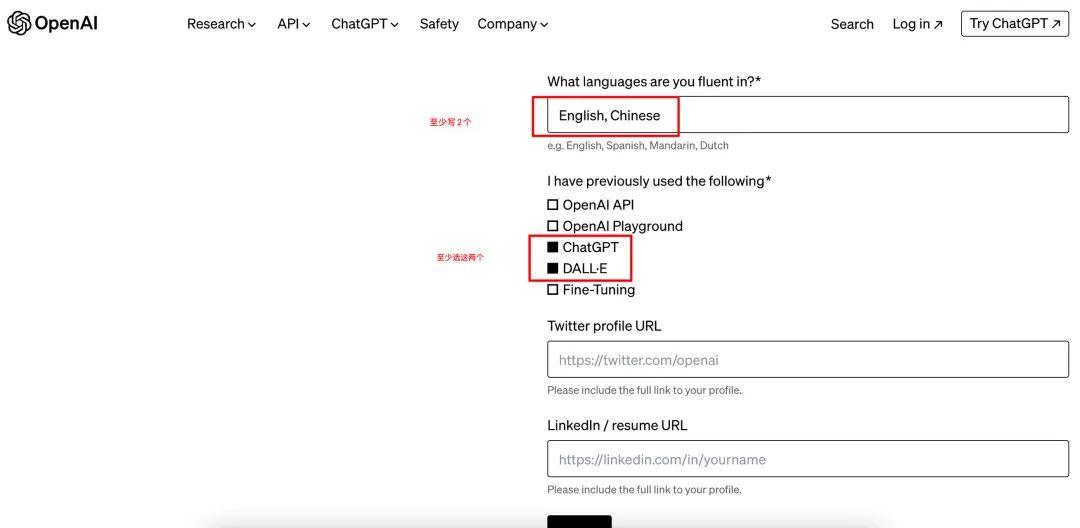
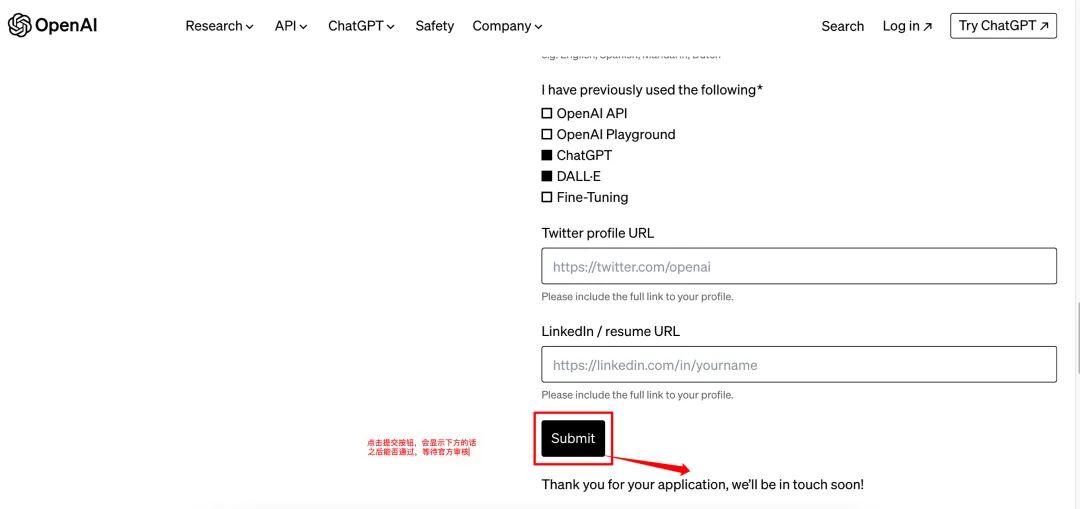
保姆级申请教程(快去申请,不知道什么时候关闭!万一申请通过了,账号就也很值钱)
更推荐先订阅升级GPT4,因为现在升级GPT4比较简单。(据官方透露的消息,OpenAI近期大概率会宣布将Sora首批开放给Chatgpt Plus用户申请使用。所以,请务必提前准备好Chatgpt Plus。)
如何注册官方GPT以及升级GPT4?参考:国内一键注册官方GPT账号教程!无需手机验证码,一站式注册OpenAI-GPT官方账号。(附:如何购买ChatGPT Plus?信用卡付款失败怎么办?使用虚拟信用卡升级ChatGPT Plus 指南
二、Sora呈现能力
1.Sora凭借“60秒一镜到底”出场即巅峰
Prompt: A stylish woman walks down a Tokyo street filled with warm glowing neon and animated city signage. She wears a black leather jacket, a long red dress, and black boots, and carries a black purse. She wears sunglasses and red lipstick. She walks confidently and casually. The street is damp and reflective, creating a mirror effect of the colorful lights. Many pedestrians walk about.

Sora拥有很强大的底层技术,可以生成具有人物和场景一致性的长达60s的视频。关于视频,可以看OpenAI官网:https://openai.com/sora
对比Runaway、PIKA、Pixverse这些AI视频领域的老牌玩家,还在对几秒几十秒的视频摩拳擦掌,单个视频长达1分钟已是碾压级的存在!在AI视频领域,2秒的视频和1分钟的视频之间,有着你难以想象的巨大技术鸿沟。
按照这个发展速度,AI辅助制作的3A游戏大作或许指日可待了!定制化的主角外形、定制化声音,可能比现在的捏脸更带感哦~
2.Sora实现了运动镜头的丝滑无缝衔接(雪后东京)

无论镜头怎么运动,人物、场景和视觉风格,都能保持神一般的一致性和稳定性!
物理世界模拟器!?
Sora还展现出超强的语义理解力,能深刻理解物理世界的存在规律与运行方式,包括特殊材质的反射与倒影,光影的变换,特定物品的运动轨迹……并将这个世界模拟出来。
OpenAI官网这样写:我们正在教AI去理解和模拟物理世界运动的模型,从而帮助人们解决需要现实世界交互的问题。
比如有一个个Sora生成的电影预告片,无论是自然风光、机甲装备、人物的羊毛头盔、太空服、皮肤肌理、神态动作,都极其逼真,转场也无比自然。

动物毛发这种对于好莱坞动画工厂都曾是难题的细节,也不在话下。

Sora可以让视频「变形」
Sora可以把两个风格迥异的视频,无比流畅地拼接在一起,让它们自然过渡,融为一体,真正做到了丝滑无缝!
前一秒还是无人机探索废墟,下一秒就是蝴蝶探索海底,你根本察觉不到啥时候切换的!

阿马尔菲海岸到冬季村:

文生图与Midjourney对比!
Prompt:Digital art of a young tiger under an apple tree in a matte painting style with gorgeous details

Prompt: Vibrant coral reef teeming with colorful fish and sea creatures

Prompt:A snowy mountain village with cozy cabins and a northern lights display, high detail and photorealistic dslr, 50mm f/1.2

三、Sora提示工程
和ChatGPT、Midjourney这些AI文本、AI绘画工具一样,Sora这种AI视频也是通过输入Prompt生成的,也就是我们俗称的「咒语」
Sora不仅听得懂「咒语」,还能精准捕捉「魔法师」的真实需求,洞察这些「咒语」在物理现实世界中的存在方式,并创造出充满生命力、情感丰富的角色。
Sora和过去的AI工具有一个极大的不同,它能自己去“发散思维”,去“扩充”提示词!
四、Sora原理剖析
核心技术就是Transformer+Diffusion
所谓Transformer+Diffusion,就是把Transformer对序列的处理能力(包括时间序列)将一张图片分成无数个小的patch,组成新的token,作为Decoder的block放到Diffusion框架中
在文本预测生成中,基本单位是 Token,Token 很好理解,就是一个单词或者单词的一部分。
Patch 的概念相对不那么好理解。
什么是patches?我们可以简单理解为一张完整的图片,被拆成NxN 的小方格,被分割成一块块的「补丁」。
这与大型语言模型中的“token”概念相似,token是文本数据的基本处理单元。
比如下面这张 224x224 的小狗图片,我们可以把它打碎成 196 张 16x16 的小图,这就叫做 Patches

但如果只是将二维的图像打碎变成patches图像块,对于视频生成任务还不够。因为视频是由包含时间序列的多张图片构成的,处理时必须考虑这些长时间范围patches序列的上下文关系,因此patches必须包含原始视频数据中的时间序列信息,因此OpenAI将patches升级成了包含时间信息的spacetime patches(时空补丁)。Spacetime patch就代表了视频中一小块特定时间和空间范围内的信息。
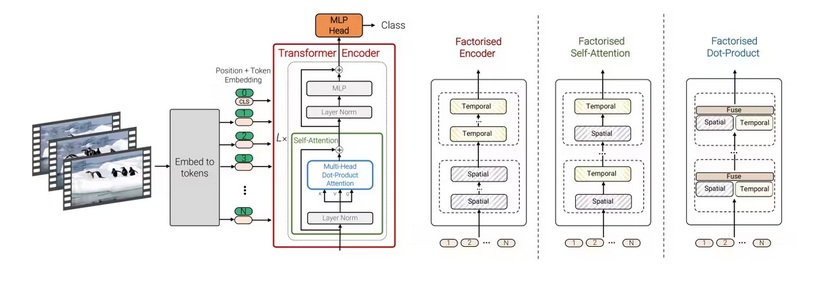
当我们理解了spacetime patches的概念之后,再来看待视频生成任务就非常好理解了。这就像chatGPT这种LLM做文本生成任务一样,从输入一段prompt开始,模型会采用的自回归的方式来预测接下来的每一个token。对于下图一系列视频帧的左上角而言,便是已知当前spacetime patches,这就如同我们给LLM输入的prompt,然后sora推测下一个spacetime patches,最后通过自回归的方式预测出组合视频画面中各个位置的spacetime patches,然后在组合起来,便得到了整个视频画面的持续运动过程。

Sora 之所以显得如此强大,在于以前的文本转视频方法需要训练时使用的所有图片和视频都要有相同的大小,这就需要大量的预处理工作来裁剪视频至适当的大小。而由于 Sora 是基于“Patch”而非视频的全帧进行训练的,它可以处理任何大小的视频或图片,无需进行裁剪。这就让 OpenAI 能够在大量的图像和视频数据上训练 Sora。因此,可以有更多的数据用于训练,得到的输出质量也会更高。例如,将视频预处理至新的长宽比通常会导致视频的原始构图丢失。一个在宽屏中心呈现人物的视频,裁剪后可能只能部分展示该人物。因为 Sora 能接收任何视频作为训练输入,所以其输出不会受到训练输入构图不良的影响。
更多原理解析请参考:OpenAI Sora:60s超长长度、超强语义理解、世界模型。浅析文生视频模型Sora以及技术原理简介
五、Sora应用展望
Sora掀起的新一轮风暴将带来哪些影响呢?
视频创作成本会大幅下降,很多需要训练动物演员、跟拍运动镜头、卡通特效制作、航拍空镜的画面,未来可以用Sora替代。
影视、娱乐、广告、设计、游戏等行业或将全新洗牌,
刚刚抵制完一轮AI的好莱坞,或许又将迎来新一轮罢工……
但是,Sora能完全取代这些行业的从业者吗?
从目前的一些不足来看,不会。为何?原因有三:
1.虽然Sora已经极力模拟物理世界,但还是还是会犯许多不符合物理规律的错误。摔落的玻璃杯掉在地板上,Sora不会生成出玻璃碎片;如果是让玻璃杯原地爆炸,散落到地上的碎片也不会是呈正态分布。
2.Sora也似乎不擅长再现多个对象和角色之间的“复杂交互”。比如,即使两次指示“吹灭蜡烛以将其熄灭”和“蜡烛的光熄灭”,火也没有熄灭。
3.Sora 必须学习一些隐式的文本到 3D、3D 变换、光线追踪渲染和物理规则,才有可能精确地模拟视频像素。它必须理解游戏引擎的概念,才有可能生成工业生产级别的视频。